Активация FlashAttention в comfyui для Nvidia Tesla V100 в linux
AI-вычисления требуют наличия большого объема быстродействующей памяти, а также использования новейшего программных модулей, в полной мере раскрывающих возможности имеющегося оборудования. Для видеокарты Nvidia Tesla V100 в comfui для этого можно установить модули Triton 3.2.0 и SageAttention 1.0.6:
pip install sageattention==1.0.6 triton=3.2.0
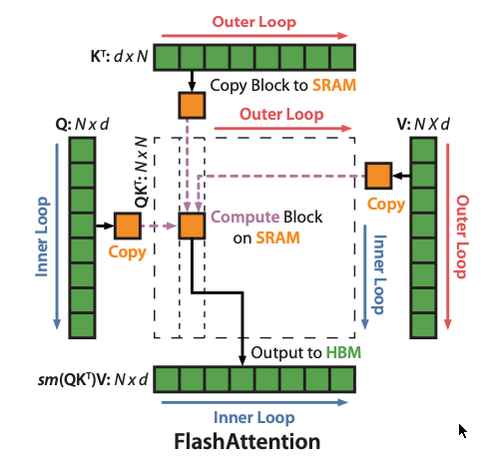
Для еще большего увеличения быстродействия вычислений на видеокарте Nvidia Tesla V100 (и на других подходящих ускорителях) в comfyui желательно использовать программный модуль FlashAttention. В нем задействован алгоритм эффективного вычисления внимания (attention) в AI-трансформерах, который значительно ускоряет инференс и уменьшает загрузку памяти на GPU.
Технология FlashAttention (Fast and Memory-Efficient Exact Attention with IO-Awareness) использует оптимизированный алгоритм работы с памятью GPU, включающий следующие элементы:
- tiling (блочное разбиение) — разбиение Q, K, V-данных на маленькие блоки, которые помещаются в кэш GPU;
- вычисление attention по блокам, без хранения полной объемной матрицы внимания в VRAM;
- использование online softmax (механизма пересчёта на лету) и переупорядочивание операций;
- минимизация количества операций чтения/записи между медленной VRAM-памятью и быстрым кешем видеокарты.
Благодаря FlashAttention, сохраняя тот же математический результат, можно увеличить скорость проведения AI-вычислений в 2–4 раза, а также снизить потребление видеопамяти.
Проверить поддержку технологии flash_attn в использующейся конфигурации comfyui можно командой:
python -c 'import flash_attn; print(f"Version: {flash_attn.__doc__}")'
На компьютере с видеокартой Nvidia Tesla V100 в штатной конфигурации comfyui отображается информация об отсутствии поддержки FlashAttention:
Traceback (most recent call last):
File "<string>", line 1, in <module> import flash_attn; print(f"Version: {flash_attn.__doc__}")
ModuleNotFoundError: No module named 'flash_attn' Из-за отсутствия модуля flash_attn при AI-вычислениях не в полной мере задействуются тензорные ядра этого графического ускорителя. В частности, не используется инструкция mma.sync.aligned.m8n8k4, необходимая для эффективного выполнения матричных операций. Она напрямую задействует Tensor Core GPU Nvidia Tesla V100, что позволяет достичь максимальной производительности и уменьшить потребление видеопамяти на 30-40%.
Для запуска comfyui с flash-attention можно использовать команду:
python main.py --enable-manager --use-flash-attention
К сожалению, полноценная поддержка flash-attn доступна только при использовании видеокарт Nvidia с архитектурой Ampere и новее. При проведении определенніх манипуляций, можно запустить модуль и на видеокартах Nvidia Turing, а также Volta (Nvidia Tesla V100).
Как добавить поддержку flash-attn в comfyui для Nvidia Tesla V100?
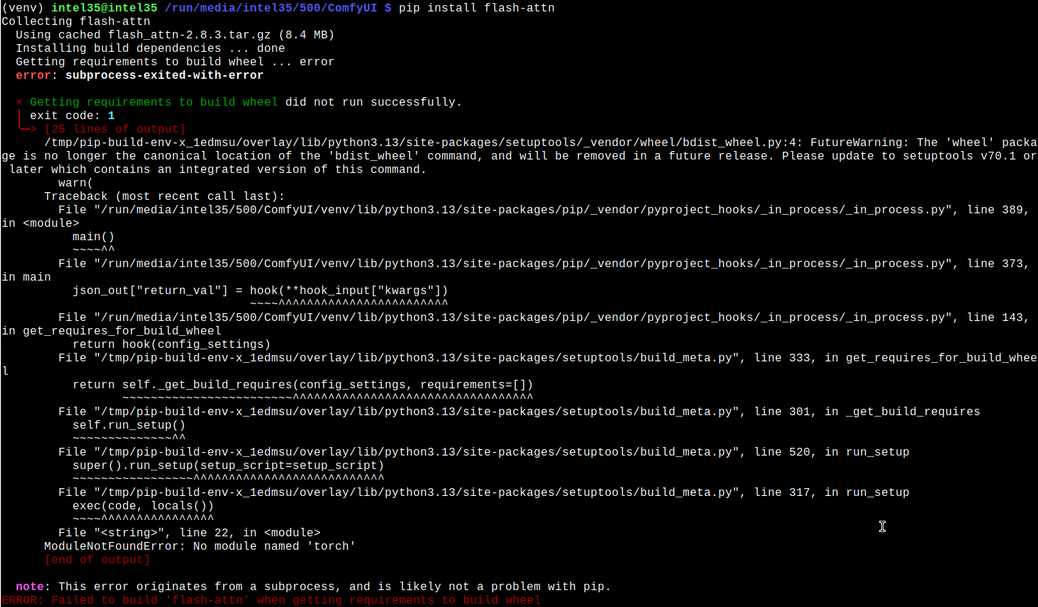
При запуске comfyui на компьютере с видеокартой Nvidia Tesla V100 в терминале появляется сообщение об опциональной возможности установить flash-attn командой:
pip install flash-attn

Однако, при попытке установить модуль FlashAttention этой командой возникает ошибка Failed to build ‘flash-attn’ when getting requirements to build wheel:
Для видеокарт Nvidia Tesla V100 в comfyui можно установить неофициальный модуль flash-attn c репозитория ai-bond, peisuke или других на github:

Чтобы добавить поддержку flash_attn для Nvidia Tesla V100, удаляем несовместимый официальный flash-attn и собираем unofficial-версию:
source ./venv/bin/activate
pip uninstall flash-attn
git clone https://github.com/ai-bond/flash-attention-v100/ && cd flash-attention-v100
pip install -r requirements.txt
# Install last one PyTorch that's support with 12.9 CUDA
pip install torch==2.10.0+cu129 --index-url https://download.pytorch.org/whl/cu129
# Check is package supports Volta
python -c "import torch; p=torch.cuda.get_device_properties(0); print(f'{p.name} SM {p.major}.{p.minor} supported')"
# If you will see Tesla V100-XXX-XXGB SM 7.0 supported all is done.
# We can compile and install project with just:
# Настройка окружения компилятора и установка по инструкции ai-bond:
export TORCH_CUDA_ARCH_LIST="7.0"
export CC=gcc-14
export CXX=g++-14
export CFLAGS="-march=native"
export CXXFLAGS="-march=native"
MAX_JOBS=1 pip install . --no-build-isolation -v
# Сборка локального форка без проверки зависимостей в gentoo с python3.14 (команда ai-bond в этой конфигурации не работает):
export TORCH_CUDA_ARCH_LIST="7.0"
export CC=gcc-14
export CXX=g++-14
export CFLAGS="-O1 -march=native"
export CXXFLAGS="-O1 -march=native"
export NVCC_APPEND_FLAGS="-O1"
MAX_JOBS=1 pip install . --ignore-installed --no-deps --no-build-isolation -v
Примечания:
Флаги --ignore-installed --no-deps нужны, так как команда pip без этих флагов пытается либо обновить системные пакеты (что ломает систему), либо падает из-за конфликтов окружения. Отрезая проверку зависимостей, контроль стабильности осуществляется самой gentoo.
Понижение оптимизации до -O1 нужно, чтобы при попытке собрать flash-attention с дефолтным для Gentoo флагом -O2 или -O3 в gcc-14 система не падала в сегфолт (Internal Compiler Error) и меньше кушала оперативную память.
Использование NVCC_APPEND_FLAGS="-O1" вызвано тем, что команда pip install . вызывает сборку через setuptools/wheel, которая не всегда правильно прокидывает системные CFLAGS в компилятор NVIDIA (nvcc). Явное указание этой переменной гарантирует, что nvcc не захлебнется при оптимизации CUDA-ядер
Ограничение MAX_JOBS=1 - это надежный способ защитить машину от падения по OOM (Out of Memory) во время параллельной сборки тяжелых C++/CUDA файлов. Даже с таким ограничением при компиляции модуля в gentoo потребление памяти периодически превышало 30GB!
Чтобы ограничить прожорливость компилятора, можно использовать такой скрипт:
export CFLAGS="-O1 -march=native"
export CXXFLAGS="-O1 -march=native"/
export NVCC_APPEND_FLAGS="-O1"
export TORCH_CUDA_ARCH_LIST="7.0"
export CC=gcc-14
export CXX=g++-14
MAX_JOBS=1 pip install . --no-build-isolation --no-deps -v
Если памяти компьютера все равно не хватает, перед сборкой создаем временный Swap на 16 ГБ:
# 1. Выделяем 16 ГБ (размер блока 1М * 16384 = 16ГБ)
sudo dd if=/dev/zero of=/swapfile bs=1M count=16384
# 2. Ограничиваем права доступа (требование безопасности Linux)
sudo chmod 600 /swapfile
# 3. Инициализируем структуру swap
sudo mkswap /swapfile
# 4. Активируем swap в текущей сессии
sudo swapon /swapfile
# 5. Выставляем максимальную агрессивность использования подкачки
sudo sysctl vm.swappiness=100
После сборки его можно отключить командой:
sudo swapoff /swapfile
либо отключить и стереть, чтобы он не занимал место на накопителе:
sudo swapoff /swapfile && sudo rm /swapfile
Успешно ли завершилась установка flash-attention-v100 можно проверить командой:
python -c "import flash_attn; print(f'Успешно! Версия: {flash_attn.__doc__}')"
Если при запуске ComfyUI возникает ошибка импорта:cannot import name '_wrapped_flash_attn_backward' from 'flash_attn.flash_attn_interface' — это означает, что С++ код расширения не содержит биндингов под новый C-API Python 3.14. Пакет установился как текстовая «заглушка», но само CUDA-ядро не скомпилировалось. Единственное рабочее решение для полноценной поддержки Tesla V100 — запустить проект на стабильном Python 3.12:
cd "/comfyui"
rm -rf venv
python3.12 -m venv venv && source ./venv/bin/activate
pip install --upgrade pip setuptools wheel ninja psutil numpy
pip install --force-reinstall --no-cache-dir torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0 --index-url https://download.pytorch.org/whl/cu129 --no-cache-dir
pip install -r requirements.txt
cd flash-attention-v100 && rm -rf build/ dist/ *.egg-info
# Флаги компилятора для Gentoo:
export TORCH_CUDA_ARCH_LIST="7.0"
export CC=gcc-14
export CXX=g++-14
export CFLAGS="-O1 -march=native"
export CXXFLAGS="-O1 -march=native"
export NVCC_APPEND_FLAGS="-O1"
# Стандартная чистая сборка без изоляции:
MAX_JOBS=1 pip install . --no-build-isolation -v
Проверка:
python -c "from flash_attn.flash_attn_interface import _wrapped_flash_attn_backward; print('Успех! Бинарные модули C++ работают на Python 3.12')"
Быстро переустановить ноды можно так:
Создаем в корне папки comfyui файл install_nodes_deps.sh:
nano install_nodes_deps.shВставляем в него следующий код:
#!/bin/bash# Путь к виртуальному окружению Python 3.12VENV_PIP="./venv/bin/pip"if [ ! -f "$VENV_PIP" ]; thenecho "❌ Ошибка: Виртуальное окружение ./venv не найдено в текущей папке!"exit 1fiecho "🔄 Обновляем базовые инструменты pip..."$VENV_PIP install --upgrade pip setuptools wheelecho "🚀 Начинаем поиск и установку зависимостей для кастомных нод..."# Обходим все подпапки в custom_nodes в поисках requirements.txtfor req in custom_nodes/*/requirements.txt; do# Проверяем, существует ли файл (на случай, если папок нет)[ -e "$req" ] || continuenode_name=$(basename "$(dirname "$req")")echo "--------------------------------------------------"echo "📦 Установка зависимостей для ноды: $node_name"echo "--------------------------------------------------"# Запускаем установку зависимостей конкретной ноды в наше venv$VENV_PIP install -r "$req"doneecho "--------------------------------------------------"echo "✅ Все найденные requirements.txt успешно обработаны!"
Сохраняем файл ( Ctrl+O, Enter, Ctrl+X) и делаем его исполняемым:
chmod +x install_nodes_deps.shЗапускаем скрипт из корня ComfyUI:
./install_nodes_deps.shПри загрузке comfyui теперь виден активный модуль flash-attn (картинка для сборки на pytorch 2.12+cu126):

AI-вычисления с flash-attn на NvidiaTesla V100 можно производить только с FP16-инструкциями, так как BF16 не поддерживается аппаратно, а FP32 — модулем flash-attn. Поэтому при работе в comfyui необходимо использовать AI-модели в формате FP16. Несмотря на это, прирост быстродействия при генерации в comfyui ощутим. При использовании неподходящей модели возникает ошибка:
Flash Attention failed, using default SDPA: FlashAttention only supports Ampere GPUs or newer.
В этом случае инференс все равно работает, используя pytorch-attn.
Чтобы использовать в ComfyUI модуль flash-attn, собранный специально для Tesla V100, в скрипт запуска можно добавить аргумент use-flash-attention:
python main.py --enable-manager --use-flash-attention
либо переменную
export FLASHATTN_V100_AUTO_PATCH=1
P.S. В списке custom-нод comfyui есть обертки для собранного неофициального Flash Attention для Nvidia Tesla V100, например, ComfyUI-ComfyUI-Flash-Attention_v100 от fearl0rd. С ее помощью в workflow можно легко подключать неофициальный модуль flash-attn (обычно перед входом модели KSampler).


Вам также может понравиться

Распределение веса модели в памяти двух видеокарт в stable-diffusion.cpp

Запуск AI-моделей в llama.cpp на AMD Radeon RX470 8GB с Vulkan в gentoo
