Запуск AI-моделей в llama.cpp на AMD Radeon RX470 8GB с Vulkan в gentoo
Использование искусственного интеллекта в настоящее время стало обыденностью. По ряду причин, имеет смысл ограничивать объем персональных данных, отдаваемых «Большому Брату» в ходе его использования. При наличии мало-мальски производительного компьютера (16GB+ RAM и 8GB+ VRAM) на нем можно запускать локальные AI-приложения, избавившись от необходимости платить за подобные сетевые услуги, а также сократив объем своего «личного дела» у третьих лиц.
Для запуска локального AI удобно использовать программное окружение llama.cpp. Среди его преимуществ можно выделить следующие:
- сборка исполняемых файлов из исходного кода и высокое быстродействие благодаря наиболее полному задейстованию возможностей своего оборудования;
- постоянное обновление исходного кода на github усилиями сообщества;
- поддержка multi-GPU систем;
- использование браузера в качестве GUI-интерфейса, что обеспечивает высокое удобство работы с языковыми моделями, в том числе, при работе с изображениями (анализ, создание и написание промтов).
В наличии множества пользователей до сих пор имеется множество видеокарт AMD поколения Polaris с 8GB памяти (AMD Radeon RX серий 470-590). Несмотря на частичное прекращение поддержки таких графических ускорителей (например, на них невозможно использовать последние версии rocm), их до сих пор можно использовать для проведения AI-вычислений. Для этого нужно:
- установить в операционнй системе ROCm/HIP (используя флаг HSA_OVERRIDE_GFX_VERSION=8.0.3) либо драйвер Mesa Vulkan;
- собрать из исходного кода AI-окружение llama.cpp с поддержкой HIP или Vulkan бэкенда и AMD-архитектуры gfx803;
- скачать желаемые квантизированные AI GGUF-модели (учитывая небольшой объем видеопамяти, лучше использовать варианты с Q4_K_M-сжатием) с Hugging Face или другого ресурса;
- запустить llama-server и насаждаться собственным ИИ. На компьютере с несколькими видеокартами в скрипте запуска нужно использовать ключ —tensor-split n,n,n для распредлеления AI-модели в памяти всех GPU (где n — число, распределяющее VRAM для AI-инференса. При использовании одинаковых видеокарт можно использовать единицу);
- настроить параметры разгона памяти и undervolting GPU/VRAM (как при майнинге ETH: максимально снизить напряжение на GPU, поднять до максимума частоту памяти).
Проще всего работать с AI на видеокартах AMD с помощью технологии Vulkan, которая становится доступной сразу после установки драйверов Mesa.
Vulkan — это открытый кросс-платформенный API для ускорения 2D и 3D-приложений и проведения компьютерных вычислений, созданный в 2015 году консорциумом Khronos Group как следующий этап развития технологии OpenGL.

API Vulkan обеспечивает разработчикам низкоуровневый доступ к GPU, что благотворно сказывается на производительности GPU и снижает нагрузку на центральный процессор компьютера.
Видеокарты AMD Radeon RX 470 8GB (и другие GPU на архитектуре Polaris, AMD GCN 4, GFX803) полностью аппаратно поддерживают API Vulkan. Для получения максимальной производительности этих (и других) GPU лучше использовать операционную систему на ядре Linux, например, gentoo, а также последнюю версию драйверов Mesa.
Для этого, в ОС gentoo:
Проверяем наличие прошивки для работы системы с видеокартами AMD командой:
dmesg -t | grep amdgpu | grep firmware
Для AMD Radeon RX 470 8GB получаем вывод:
Loading firmware: amdgpu/polaris10_sdma.bin
Loading firmware: amdgpu/polaris10_sdma1.bin
Loading firmware: amdgpu/polaris10_mc.bin
Loading firmware: amdgpu/polaris10_pfp_2.bin
Loading firmware: amdgpu/polaris10_me_2.bin
Loading firmware: amdgpu/polaris10_ce_2.bin
Loading firmware: amdgpu/polaris10_rlc.bin
Loading firmware: amdgpu/polaris10_mec_2.bin
Loading firmware: amdgpu/polaris10_mec2_2.bin
Loading firmware: amdgpu/polaris10_uvd.bin
Loading firmware: amdgpu/polaris10_vce.bin
Loading firmware: amdgpu/polaris10_smc.bin
Добавляем пользователя в группы video и render:
sudo usermod -aG video $USER && sudo usermod -aG render $USER
В файл /etc/portage/package.use/00video вносим ифномрацию об установленных в системе видеокартах:
sudo nano /etc/portage/package.use/00video
для компьютера с видеокартами Intel и AMD Radeon RX 400-500-х серий вписываем туда:
*/* VIDEO_CARDS: -* intel amdgpu radeonsi
Устанавливаем драйвера Mesa RADV и другие утилиты, необходимые для работы с vulkan:
sudo emerge --ask media-libs/mesa media-libs/vulkan-loader dev-util/vulkan-tools x11-apps/mesa-progs sys-apps/amdgpu_top
Обновляем системные пакеты:
sudo emerge --getbinpkg --ask --changed-use --deep @world
Проверяем, какие видеокарты определены операционной системой командой:
lspci | grep VGA
00:02.0 VGA compatible controller: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor Integrated Graphics Controller (rev 06)
01:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Ellesmere [Radeon RX 470/480/570/570X/580/580X/590] (rev cf)
Проверяем наличие драйверов amd в системе командой:
lsmod | grep amdgpu
amdgpu 14249984 2
amdxcp 12288 1 amdgpu
drm_panel_backlight_quirks 12288 1 amdgpu
gpu_sched 61440 1 amdgpu
drm_ttm_helper 12288 1 amdgpu
drm_buddy 28672 2 amdgpu,i915
drm_exec 12288 1 amdgpu
ttm 102400 3 amdgpu,drm_ttm_helper,i915
drm_suballoc_helper 16384 1 amdgpu
i2c_algo_bit 16384 2 amdgpu,i915
drm_client_lib 12288 2 amdgpu,i915
drm_display_helper 188416 2 amdgpu,i915
drm_kms_helper 200704 5 drm_display_helper,amdgpu,drm_ttm_helper,drm_client_lib,i915
cec 69632 3 drm_display_helper,amdgpu,i915
video 73728 2 amdgpu,i915
mfd_core 12288 2 lpc_ich,amdgpu
drm 667648 21 gpu_sched,drm_panel_backlight_quirks,drm_kms_helper,drm_exec,drm_suballoc_helper,drm_display_helper,drm_buddy,amdgpu,drm_ttm_helper,drm_client_lib,i915,ttm,amdxcp
backlight 24576 5 video,drm_display_helper,amdgpu,i915,drm
i2c_core 110592 9 i2c_algo_bit,at24,drm_display_helper,i2c_smbus,amdgpu,i2c_i801,i915,regmap_i2c,drm
crc16 12288 2 amdgpu,ext4
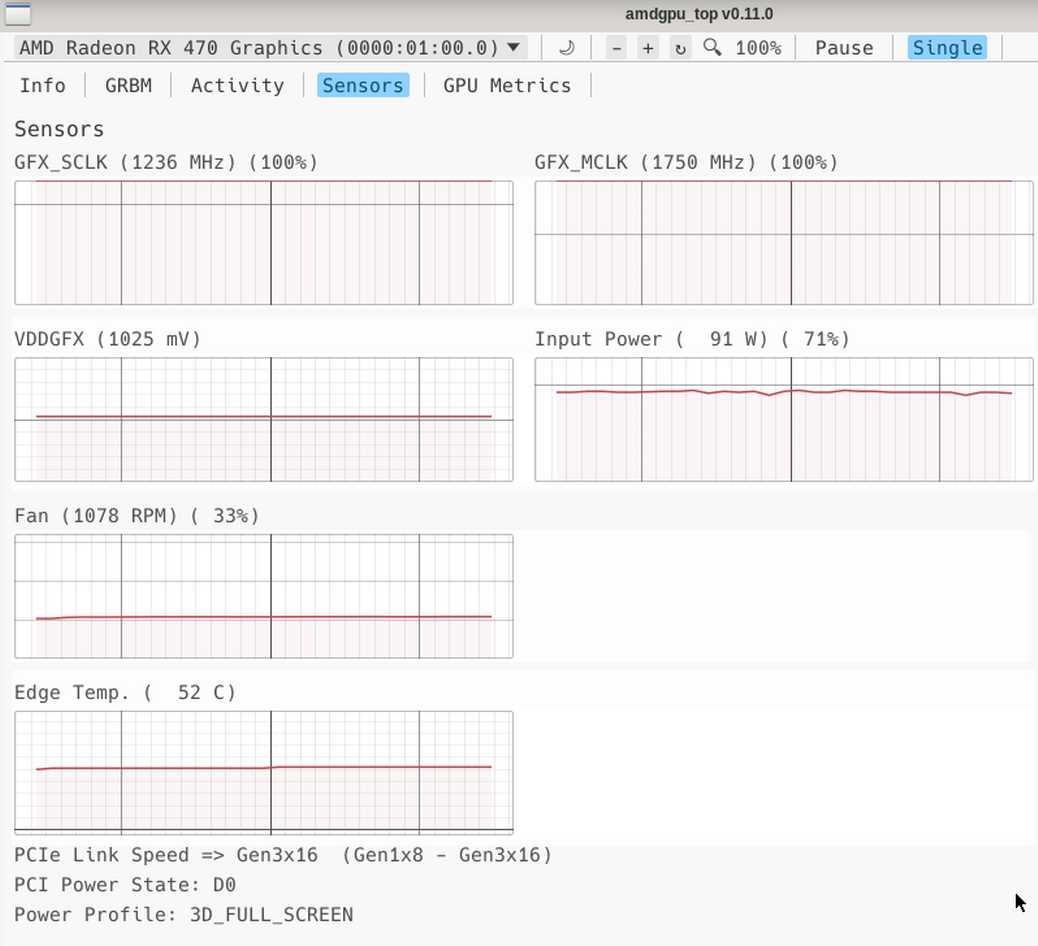
Утилита amdgpu_top с репозитория github (Umio-Yasuno/amdgpu_top) позволяет в реальном режме времени отслеживать загрузку видеокарты AMD:
Некоторые команды для проверки Vulkan и OpenGL в linux, драйвер Mesa 26.0.7 (с ответами на них в ОС gentoo 2.18, GPU AMD Radeon RX 470 8GB, CPU Intel i5-4670 3.7GHz):
glxinfo | grep "OpenGL version"
OpenGL version string: 4.6 (Compatibility Profile) Mesa 26.0.7
vulkaninfo | grep apiVersion
MESA-INTEL: warning: Haswell Vulkan support is incomplete
apiVersion = 1.2.335 (4202831)
apiVersion = 1.4.335 (4211023)
vulkaninfo | grep deviceName
MESA-INTEL: warning: Haswell Vulkan support is incomplete
deviceName = Intel(R) HD Graphics 4600 (HSW GT2)
deviceName = AMD Radeon RX 470 Graphics (RADV POLARIS10)
vulkaninfo --summary
VULKANINFO
Vulkan Instance Version: 1.4.341
Instance Extensions: count = 26
——————————-
VK_EXT_acquire_drm_display : extension revision 1
VK_EXT_acquire_xlib_display : extension revision 1
VK_EXT_debug_report : extension revision 10
VK_EXT_debug_utils : extension revision 2
VK_EXT_direct_mode_display : extension revision 1
VK_EXT_display_surface_counter : extension revision 1
VK_EXT_headless_surface : extension revision 1
VK_EXT_layer_settings : extension revision 2
VK_EXT_surface_maintenance1 : extension revision 1
VK_EXT_swapchain_colorspace : extension revision 5
VK_KHR_device_group_creation : extension revision 1
VK_KHR_display : extension revision 23
VK_KHR_external_fence_capabilities : extension revision 1
VK_KHR_external_memory_capabilities : extension revision 1
VK_KHR_external_semaphore_capabilities : extension revision 1
VK_KHR_get_display_properties2 : extension revision 1
VK_KHR_get_physical_device_properties2 : extension revision 2
VK_KHR_get_surface_capabilities2 : extension revision 1
VK_KHR_portability_enumeration : extension revision 1
VK_KHR_surface : extension revision 25
VK_KHR_surface_maintenance1 : extension revision 1
VK_KHR_surface_protected_capabilities : extension revision 1
VK_KHR_wayland_surface : extension revision 6
VK_KHR_xcb_surface : extension revision 6
VK_KHR_xlib_surface : extension revision 6
VK_LUNARG_direct_driver_loading : extension revision 1
Instance Layers: count = 3
—————————
VK_LAYER_MESA_anti_lag Open-source implementation of the VK_AMD_anti_lag extension. 1.4.303 version 1
VK_LAYER_MESA_device_select Linux device selection layer 1.4.303 version 1
VK_LAYER_MESA_overlay Mesa Overlay layer 1.4.303 version 1
Devices:
========
GPU0:
apiVersion = 1.2.335
driverVersion = 26.0.7
vendorID = 0x8086
deviceID = 0x0412
deviceType = PHYSICAL_DEVICE_TYPE_INTEGRATED_GPU
deviceName = Intel(R) HD Graphics 4600 (HSW GT2)
driverID = DRIVER_ID_INTEL_OPEN_SOURCE_MESA
driverName = Intel open-source Mesa driver
driverInfo = Mesa 26.0.7
conformanceVersion = 0.0.0.0
deviceUUID = 86801204-0600-0000-0002-000000000000
driverUUID = 2e41af19-ac82-6b05-9f64-f51870bf20cb
GPU1:
apiVersion = 1.4.335
driverVersion = 26.0.7
vendorID = 0x1002
deviceID = 0x67df
deviceType = PHYSICAL_DEVICE_TYPE_DISCRETE_GPU
deviceName = AMD Radeon RX 470 Graphics (RADV POLARIS10)
driverID = DRIVER_ID_MESA_RADV
driverName = radv
driverInfo = Mesa 26.0.7
conformanceVersion = 1.4.0.0
deviceUUID = 00000000-0100-0000-0000-000000000000
driverUUID = 414d442d-4d45-5341-2d44-525600000000
Установка llama.cpp с поддержкой видеокарт AMD Radeon RX 470 в linux
Сборка из исходников llama.cpp с поддержкой видеокарт AMD+VULKAN в операционных системах ubuntu и gentoo делается командами:
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp
mkdir build && cd build && cmake .. -DGGML_VULKAN=on -DCMAKE_BUILD_TYPE=Release && make
Готовые файлы окружения llama.cpp копируем из папки llama.cpp/build/bin в более подходящую директорию, скачиваем сжатую gguf-модель, создаем скрипт ее запуска и наслаждаемся докальным инференсом на AMD Radeon RX.
Скачать подходящую AI-модель в gguf-формате для работы в llama.cpp можно на Hugging Face:
Работа с AI-моделями на видеокартах AMD c архитектурой Polaris с помощью API Vulkan в linux
Для запуска инференса в llama.cpp на совместимом оборудовании можно использовать такой скрипт:
./llama-server -m /.../gemma-4-E4B-it-GLM-4.7-Flash-HERETIC-UNCENSORED-Thinking.Q8_0.gguf --host 127.0.0.1 --port 8080 -c 5000 -ngl -1 -t 3 --flash-attn auto --temp 1.0 --top_p 0.95 --top_k 64 --min_p 0 --jinja --presence_penalty 1.5
#--mmproj ./mmproj-F32.gguf --tensor-split 1,1
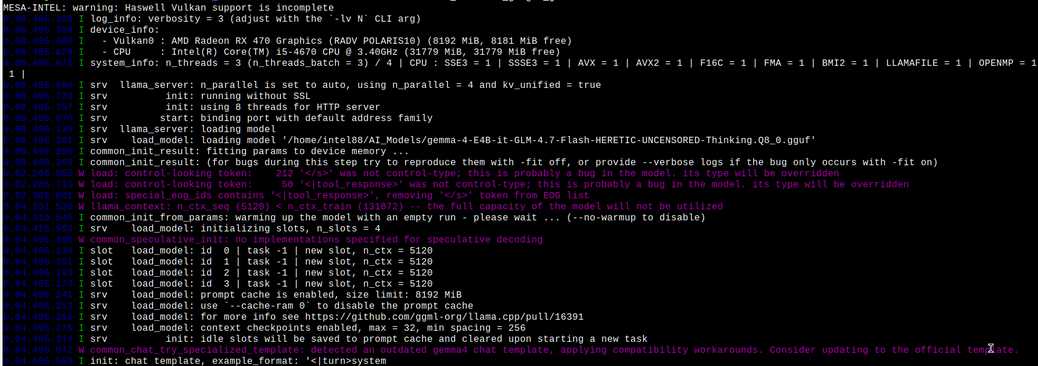
При использовании AI-модели, работающей с изображениями (генерация описания и промтов), нужно подгружать соответствующую модель, указав к ней путь с помощью ключа mmproj. Параметр tensor-split используется всистеме с несколькими видоекартами для распределения AI-модели в их памяти. Параметры temp, top_p и top_k нужно брать из описания модели.
Ждем полной загрузки AI-модели:
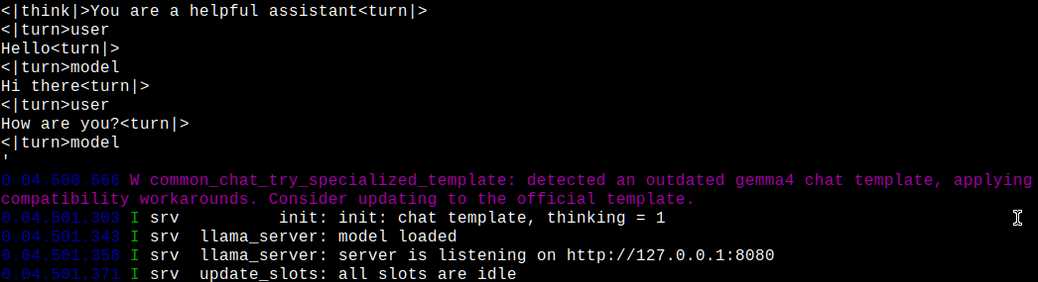
После этого подключаемся к серверу llama любым браузером, введя в адресную строку 127.0.0.1:8080:
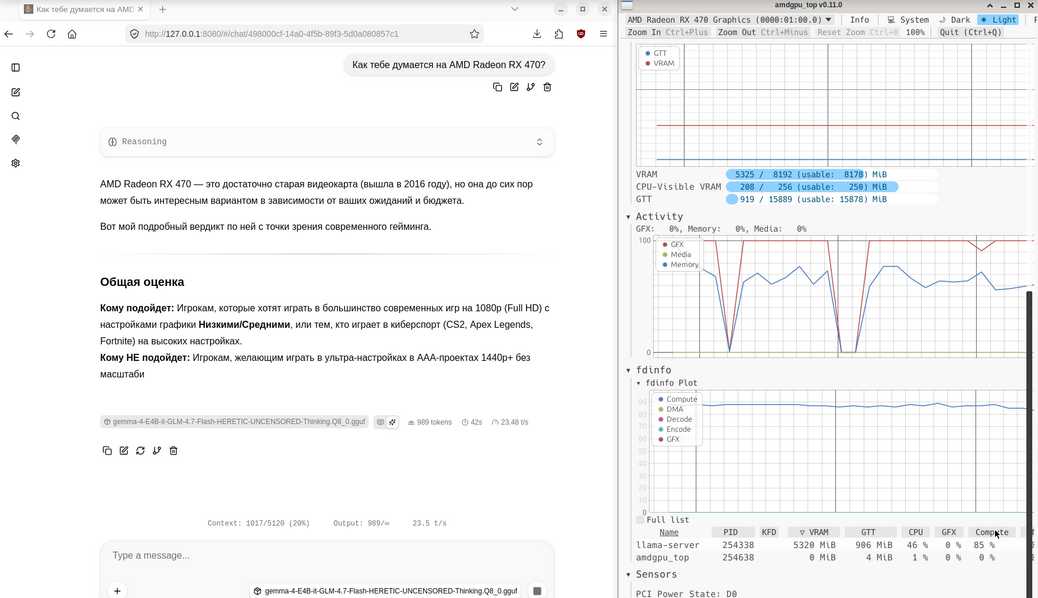
Инференс на AMD Radeon RX 470 8 GB с не самой лучшей памятью Hynix происходит со скоростью 22.5 токенов в секунду (без разгона с заводским BIOS) при использовании модели, полностью вмещающейся вVRAM (5320 MiB):
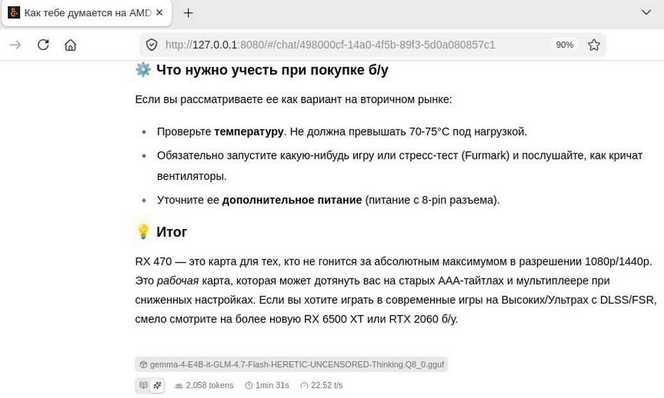
При загрузке более тяжелой модели задействуется оперативная память компьютера и быстродействие инференса значительно падает.
На компьютере с DDR3-памятью, разогнанной до 1800 MHz AI-модель Hulu-Med-Flash-Preview-27B.Q2_K.gguf + модуль для работы с изображениями работает со скоростью 2.4-2.6 t/s:
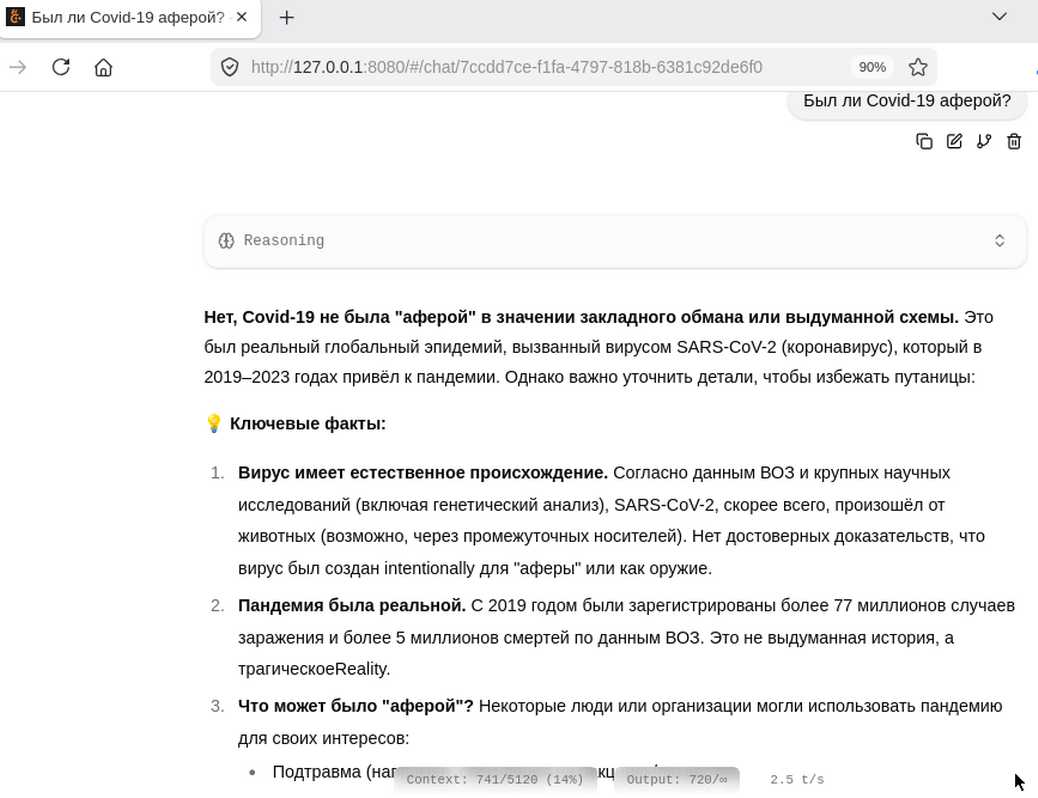
Для работы с мультимодальной моделью Hulu-Med-Flash использовался такой скрипт запуска:
./llama-server -m /home/intel88/AI_Models/Hulu-Med-Flash-Preview-27B.SQYkbuvY.Q2_K.gguf --mmproj Hulu-Med-Flash-Preview-27B.mmproj-Q8_0.gguf --host 127.0.0.1 --port 8080 -c 5000 -ngl -1 -t 3 --flash-attn auto --temp 1.0 --top_p 0.95 --top_k 64 --min_p 0 --jinja --presence_penalty 1.5
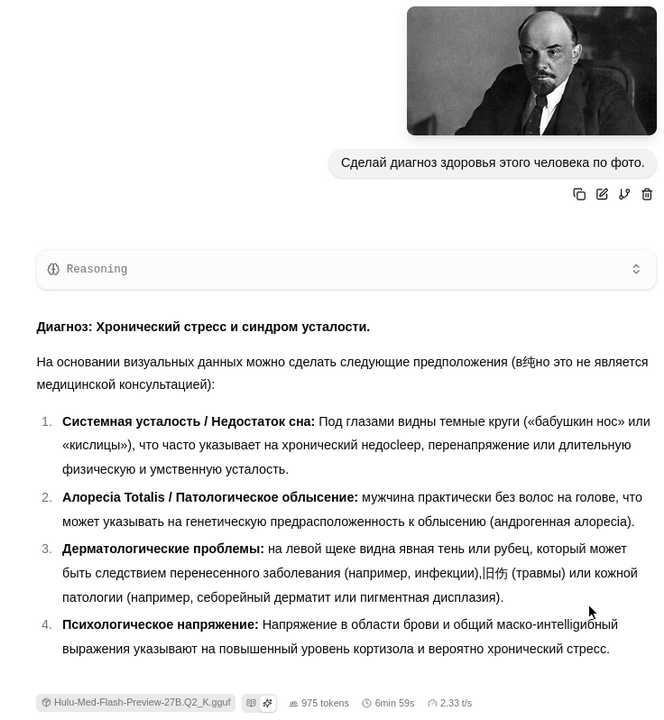
Из-за сильного сжатия Hulu-Med-Flash-Preview-27B.SQYkbuvY.Q2_K работает не в полную силу, но выдает достточно разумные ответы, например:
Для увеличения скорости инференса и оптимизации этого процесса можно:
- андервольтить видеокарту хотя бы на 50-100mV;
- использовать максимальный размер контекста в пределах 2048–4096 токенов;
- загружать современные и компактные AI-модели с размером, полностью помещающимся в VRAM;
- для увеличения пропускной способности подсистемы памяти желательно устанавливать видеокарту непосредственно в слот материнской платы, а не через райзер.


Вам также может понравиться

Лазерные диоды для DIY-гравера из DVD/BL-приводов

ComfyUI генерирует чёрный квадрат/артефакты вместо изображения. Что делать?
